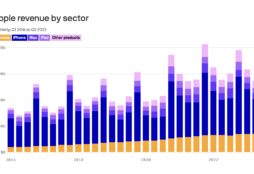
Mi columna en Invertia de esta semana se titula «La España pionera» (pdf), y es una reflexión provocada por el dato de que, en España, la mitad de los adultos dependen o bien de algún tipo de ayuda, de una pensión o un empleo público. Una situación que contribuye en gran
…